
The Introduction of Entity and Attribute
In the world of data modeling and database design, entities and attributes play crucial roles in organizing and structuring data. Entities represent distinct objects or concepts, while attributes describe the specific characteristics or properties of those entities. Understanding the difference between entities and attributes is essential for accurately representing and organizing data within a database.
Entities can be thought of as the main objects or concepts of interest in a domain. They represent real-world entities such as customers, products, employees or orders. Attributes, Provide additional information about entities. They describe the specific features, qualities or characteristics of entities, such as the name, age, address or price.
Entities and attributes work together to form the foundation of data models and databases. Entities may be organized in tables or collections, with each instance representing one row or document within that table or collection. Attributes, represented as columns or fields, define the specific information associated with each entity instance.
Proper identification and definition of entities and attributes are crucial for data integrity and consistency. Clear understanding of their relationship allows for accurate representation, categorization and organization of data. This understanding enables efficient data storage, retrieval and manipulation, supporting effective database management.
In this content outline, we will explore the definitions and characteristics of entities and attributes, their relationship to each other and to data modeling components and the importance of understanding their distinction. By grasping the difference between entities and attributes, we can establish a solid foundation for data modeling and database design, ensuring accurate representation and efficient management of data.
What is an Entity?
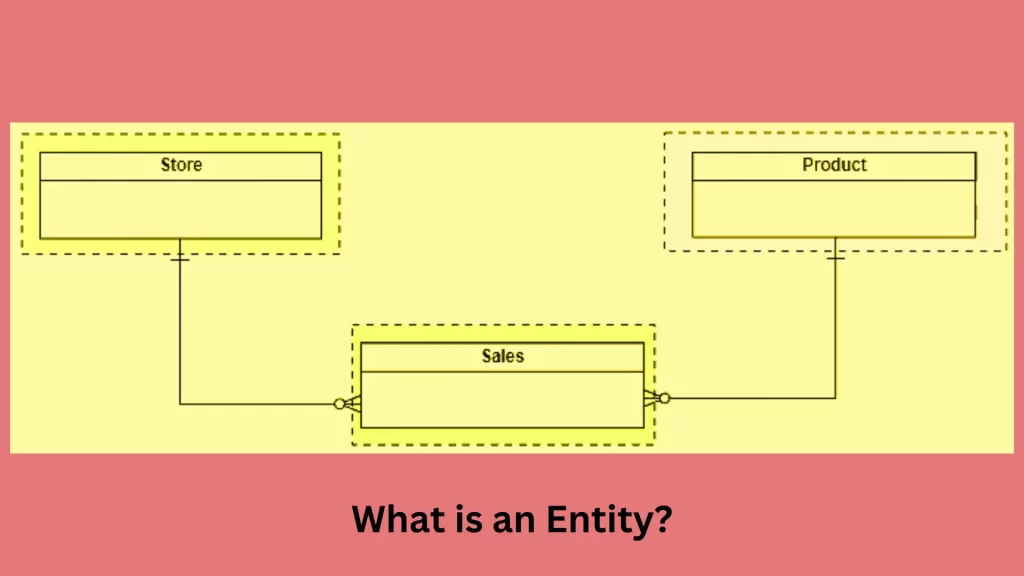
An entity refers to a distinct and individual object, concept or thing that exists in the real world and can be uniquely identified. It represents a particular type of object or entity class in the context of data modeling and database design.
Entities can be concrete or abstract and can exist independently or have relationships with other entities. They are often represented as nouns or noun phrases that represent real-world objects or concepts. For example, in a business domain, entities could include customers, products, employees or orders. In a social media context, entities could include users, posts, comments or likes.
Entities serve as the building blocks of data models and databases. Entities are typically represented in databases using tables or collections containing entities; each instance of an entity corresponds with either a row or document in this collection or table. Entities help define the structure, organization and relationships within a database system, facilitating efficient data storage, retrieval and manipulation.
Understanding entities is fundamental for accurately representing and categorizing objects or concepts within a domain. They provide the basis for organizing and managing data, allowing for effective data modeling, database design and data management processes.
Types of Entities
Data modeling entities can be classified according to characteristics and relationships. Here are a few types of common entities:
- Strong Entities: Strong entities are entities that can exist independently and have their own unique identifier (or primary key). Existence is independent from other entities or processes. For example, in a customer management system, the “Customer” entity can be considered a strong entity as it can exist on its own.
- Weak Entities: Weak entities are entities that depend on another entity for their existence. They do not have a unique identifier on their own and are identified through their relationship with a strong entity. They typically have a foreign key that links them to a strong entity. An example of a weak entity could be the “Order Item” entity, which depends on the “Order” entity for its existence.
- Associative Entities: Associative entities, also known as junction entities or many-to-many entities, are used to represent relationships between other entities. They are introduced when a relationship between two entities has attributes of its own. For example, in a database modeling a bookstore, an “Author” entity and a “Book” entity may have a many-to-many relationship, which can be represented by an associative entity called “Authorship” with its own attributes.
- Subtypes and Supertypes: At times, entities can exist within an organizational hierarchy wherein one entity serves as the subtype or specialization for another – known as supertype. This is known as entity inheritance or generalization/specialization. For example, in an employee management system, a “Manager” entity can be a subtype of the “Employee” entity, inheriting common attributes and behaviors.
- Aggregates: An aggregate entity represents a collection or group of related entities. It is treated as a single unit, and its attributes and operations are defined collectively for the group. For instance, in an online shopping system, the “Shopping Cart” entity can be considered an aggregate entity that contains multiple “Product” entities and their associated quantities.
- Historical Entities: Historical entities represent entities that have a temporal aspect or record historical data. They are used to capture and manage information about past states or versions of an entity. For example, in a version control system, a “Document” entity may have historical versions stored as separate entities to track changes over time.
These are just a few examples of entity types commonly encountered in data modeling. Types and classifications may depend on the modelled system’s domain or requirements. It’s important to identify and define the appropriate entity types to accurately represent and organize data within a database system.
Examples of Entities
Here are some examples of entities in different domains:
- Customer: In a retail or e-commerce system, the “Customer” entity represents individuals or organizations who make purchases. It may have attributes such as customer ID, name, email address, shipping address and contact information.
- Product: The “Product” entity represents items or goods that are available for sale. It may have attributes like product ID, name, description, price, quantity and category.
- Employee: In a human resources management system, the “Employee” entity represents individuals who work within an organization. It may have attributes such as employee ID, name, job title, department, hire date and salary.
- Order: The “Order” entity represents a customer’s request to purchase one or more products. These may include attributes such as order ID, date, customer ID and payment method.
- Bank Account: In a banking system, the “Bank Account” entity represents individual accounts held by customers. It may have attributes such as account number, account type, balance, owner ID and transaction history.
- Flight: In an airline reservation system, the “Flight” entity represents a scheduled flight. It may have attributes like flight number, departure airport, arrival airport, departure time, arrival time and available seats.
- Patient: In a healthcare system, the “Patient” entity represents individuals receiving medical care. It may have attributes such as patient ID, name, date of birth, gender, medical history and contact details.
- Event: In an event management system, the “Event” entity represents a planned gathering or occasion. It may have attributes like event ID, name, date, location, organizer and attendee list.
- Supplier: “Suppliers”, when applied to supply-chain management systems, refers to companies or individuals that supply goods or services directly to a company. It may have attributes such as supplier ID, name, contact information and product catalog.
- Social Media Post: In a social media platform, the “Post” entity represents individual user-generated posts. It may have attributes like post ID, content, date and time of posting, likes, comments and author information.
These examples illustrate how entities represent different real-world objects or concepts and play a central role in data modeling and database design. The attributes associated with these entities provide specific details and characteristics of each entity instance, allowing for efficient data management and organization.
What is an Attribute?

Attributes provide extra details about an entity by giving more insight into its features or characteristics; providing further details that help describe and distinguish entities within a database or data model.
Attributes provide valuable details about entities. For example, attributes define what kinds of data an entity can store such as text, dates, numeric values or Booleans values. Attributes can be displayed as columns or fields within tables, collections or lists and each attribute represents specific pieces of data associated with an entity.
Types of Attributes
Data attributes can be organized based on characteristics and behaviors, with common examples including the following types:
- Simple Attribute: A simple attribute represents a single, indivisible value for an entity. It is not composed of subparts or components. Examples include attributes like “Name,” “Age,” or “Email.”
- Composite Attribute: Composite attributes consist of several sub attributes that each represent part of or contribute to the attribute as an entity. It represents a more granular level of information. Address attributes may include sub attributes such as Street Name, State, City Name and Postal Code.
- Single-Valued Attribute: A single-valued attribute holds a single value for each entity instance. It represents a single occurrence of information. For instance, the attribute “Date of Birth” would typically have one value for each person.
- Multi-Valued Attribute: A multi-valued attribute can hold multiple values for a single entity instance. It represents multiple occurrences of information. For example, the attribute “Phone Number” for a customer entity may have multiple values to account for various contact numbers.
- Derived Attribute: A derived attribute is not stored explicitly but is derived or calculated based on other attributes or entities. It is derived through calculations or expressions and can be computed dynamically. An example is a “Total Price” attribute, which can be derived by multiplying the “Quantity” attribute with the “Unit Price” attribute.
- Null-Valued Attribute: A null-valued attribute allows for the absence of a value. It can be left empty or contain a null value, indicating the lack of a meaningful or known value for that attribute. Null values are often used when data is missing or unknown.
- Key Attribute: A key attribute uniquely identifies an entity instance within an entity set. It is used to establish the uniqueness of an entity and is often chosen as the primary key for a table or collection. For example, a “Customer ID” attribute can serve as a key attribute to uniquely identify customers.
- Foreign Key Attribute: A foreign key attribute establishes a relationship between two entities by referencing the primary key of another entity. It represents a connection or association between entities. For instance, an “Order” entity may have a foreign key attribute referencing the “Customer ID” attribute of the “Customer” entity.
- Candidate Attribute: A candidate attribute is an attribute that could potentially serve as a key attribute but is not currently designated as the primary key. It possesses the uniqueness property but is not chosen as the primary key due to various factors.
- Metadata Attribute: Metadata attributes provide additional information about other attributes or entities. They describe the characteristics, properties or context of the data. Examples include attributes like “Data Type,” “Creation Date” or “Last Modified By.”
These are some common types of attributes found in data modeling. The specific types and classifications of attributes may vary depending on the requirements and nature of the data being modeled. Proper identification and definition of attribute types are crucial for accurately representing and organizing data within a database system.
Examples of Attributes
Here are some examples of attributes in different domains:
Customer Entity:
- Customer ID: A unique identifier for each customer.
- Name: The name of the customer.
- Email: The email address of the customer.
- Age: The age of the customer.
- Address: The residential address of the customer.
Product Entity:
- Product ID: A unique identifier for each product.
- Name: The name of the product.
- Description: A brief description of the product.
- Price: The price of the product.
- Quantity: The available quantity of the product in stock.
Employee Entity:
- Employee ID: A unique identifier for each employee.
- Name: The name of the employee.
- Job Title: The job title or position of the employee.
- Department: The department in which the employee works.
- Salary: The salary or wage of the employee.
Order Entity:
- Order ID: A unique identifier for each order.
- Order Date: The date when the order was placed.
- Customer ID: The ID of the customer who placed the order.
- Payment Method: The method of payment used for the order.
- Shipping Address: The address to which the order should be shipped.
Bank Account Entity:
- Account Number: A unique identifier for each bank account.
- Account Type: The type of the bank account, such as savings or checking.
- Balance: The current balance in the bank account.
- Owner ID: The ID of the account owner.
- Date Opened: The date when the account was opened.
Flight Entity:
- Flight Number: A unique identifier for each flight.
- Departure Airport: The airport from which the flight departs.
- Arrival Airport: The airport at which the flight arrives.
- Departure Time: The scheduled departure time of the flight.
- Arrival Time: The scheduled arrival time of the flight.
Patient Entity:
- Patient ID: A unique identifier for each patient.
- Name: The name of the patient.
- Date of Birth: The date of birth the patient.
- Gender: The gender of the patient.
- Medical History: The medical history or relevant health information of the patient.
Event Entity:
- Event ID: A unique identifier for each event.
- Event Name: The name or title of the event.
- Date: The date when the event takes place.
- Location: The location or venue of the event.
- Organizer: The entity or organization organizing the event.
Supplier Entity:
- Supplier ID: A unique identifier for each supplier.
- Name: The name of the supplier.
- Contact Information: The contact details of the supplier, such as phone number or email.
- Product Catalog: The list of products or services offered by the supplier.
Social Media Post Entity:
- Post ID: A unique identifier for each post.
- Content: The content or message of the post.
- Date and Time: Date and time of post creation.
- Likes: The number of likes received by the post.
- Author Information: The information about the user who authored the post.
These examples illustrate how attributes provide specific details and characteristics of entities within a database. Attributes play a crucial role in accurately representing and organizing data, enabling efficient data storage, retrieval and manipulation.
Comparison table of Entity and Attribute
Below is a comparison table highlighting the key differences between entities and attributes:
| Aspect | Entity | Attribute |
|---|---|---|
| Definition | Represents a distinct object or concept within a system. | Describes the characteristics or properties of an entity. |
| Examples | Customer, Product, Order | Name, Age, Address, Quantity |
| Purpose | Represents a discrete unit of information. | Provides additional details about entities. |
| Identification | Identified by a unique identifier called a primary key. | Identified by their association with an entity. |
| Relationships | Can have relationships with other entities. | Do not have relationships with other attributes. |
| Grouping | Can be grouped into hierarchies or categories. | Exist within entities and are associated with specific entities. |
| Structure | Composed of one or more attributes. | Consist of a name and a data type. |
| Storage | Entities are stored as tables or collections. | Attributes are stored as columns or fields within entity tables. |
| Integrity | Have integrity constraints such as primary keys and foreign keys. | Are subject to constraints defined by entities. |
| Unique Values | Each entity instance has a unique identity. | Attribute values can be unique or non-unique within an entity. |
| Dependencies | Entities can be dependent on other entities. | Attributes can be dependent on other attributes or entities. |
How to Identify Entities and Attributes

Entity and attribute identification plays a pivotal role in database design and data modeling. Here are a few steps that will assist with this identification:
- Understand the Domain: Gain a clear understanding of the domain or subject matter for which you are designing the database. This involves studying the business requirements, processes and the information that needs to be captured and managed.
- Identify Nouns: Look for nouns or noun phrases in the domain description. Nouns often represent entities in the system. For example, in an e-commerce system, nouns like “customer,” “product,” “order,” and “payment” suggest potential entities.
- Determine Entity Boundaries: Define the boundaries of each entity. Consider what makes each entity a distinct and separate object. Entities should be self-contained and represent a real-world object or concept. Avoid mixing attributes from multiple entities into a single entity.
- Identify Unique Identifiers: Determine the attribute(s) that uniquely identify each entity instance. This unique identifier is often referred to as the primary key. It should be a property or combination of properties that uniquely distinguish one entity instance from another.
- Identify Descriptive Attributes: Identify the descriptive attributes that provide additional information about each entity. These attributes describe the characteristics, properties or qualities of the entity. An entity representing customers might possess attributes like name, email address and telephone number.
- Analyze Relationships: Consider the relationships between entities. Relationships represent associations or connections between entities and may influence the identification of attributes. If two entities exist – such as “order” and “customer”, for instance – then each could possess an attribute referencing its primary key from one another. For instance, in this scenario “order” would contain a foreign key attribute that references primary key from “customer”.
- Normalize the Data: Apply the principles of database normalization to eliminate data redundancy and ensure data integrity. This may involve decomposing entities with composite attributes into separate entities, identifying and removing redundant attributes and ensuring each attribute depends only on the entity’s primary key.
- Refine and Validate: Review and refine the identified entities and attributes to ensure they accurately represent the domain and fulfill the requirements. Validate the choices with stakeholders, subject matter experts and through data analysis to ensure the chosen entities and attributes capture the necessary information accurately.
Remember that the process of identifying entities and attributes is iterative and may require multiple iterations as you gain a deeper understanding of the domain and refine your data model. Collaboration between stakeholders and subject-matter experts is integral in order to ensure that identified entities and attributes align with the requirements of a system.
Entity Identification
Entity Identification is the process of recognizing and defining entities within an environment or system. Entities represent important concepts or objects which require attention in a database environment, making identification important. Below are several steps which will assist with this task:
- Understand the Domain: Gain a clear understanding of the domain or subject matter for which you are designing the database. This involves studying the business processes, requirements and the scope of the system.
- Analyze the Requirements: Review the requirements documentation and conduct interviews or discussions with stakeholders and subject matter experts. Identify the main objects, concepts or real-world entities that are central to the domain.
- Look for Nouns: Scan the domain description or documentation for nouns or noun phrases. Nouns often indicate potential entities. At universities, their management systems may include nouns like “student,””course,””faculty,”,”department”and “class.”
- Identify Distinct Objects: Determine the distinct objects or things that need to be represented in the system. Focus on objects that have unique identities and can be considered as separate entities. Avoid including attributes from multiple objects into a single entity.
- Consider Relationships: Analyze the relationships between different objects or concepts. Relationships represent associations, dependencies, or interactions between entities. For example, a “student” entity may have a relationship with a “course” entity indicating enrollment or participation.
- Define Entity Boundaries: Determine the boundaries of each entity by considering what makes it a separate and self-contained object. Entities should encapsulate all the relevant attributes and behaviors associated with them. For example, a “product” entity should include all attributes related to the product, price, description and quantity.
- Identify Unique Identifiers: Determine the attribute(s) that uniquely identify each entity instance. This unique identifier, often referred to as the primary key, ensures that each entity instance can be uniquely identified and distinguished from others. Your choices of attributes could range from just one attribute or multiple attributes combined.
- Validate with Stakeholders: Collaborate with stakeholders, subject matter experts and end-users to validate the identified entities. Gather feedback and ensure that the identified entities align with the requirements and accurately represent the domain.
Remember that entity identification is an iterative process and it may require refinement and adjustments as you gain more insights and feedback. It’s important to involve relevant stakeholders throughout the process to ensure that the identified entities meet the needs of the system and provide an accurate representation of the domain being modeled.
Attribute Identification
Attribute identification refers to identifying characteristics or properties which describe an entity within a data model or database, typically to provide extra details and define unique aspects about an object or person. Here are a few tips that might help with attribute recognition:
- Understand the Domain: Gain a clear understanding of the domain or subject matter for which you are designing the database. This involves studying the business processes, requirements and the scope of the system.
- Analyze the Entities: Review the identified entities and their definitions. Understanding the nature and purpose for each entity as well as data that needs to be captured and preserved are vital steps.
- Identify Descriptive Information: Consider the descriptive information that needs to be associated with each entity. These are the properties or characteristics that describe and differentiate the entities. As an example, customer entities could include attributes such as name, email, phone and address.
- Determine Data Types: Determine the appropriate data types for the attributes. Data types refer to various data elements which define what can be stored as attributes – for instance text, dates, numeric values or Boolean values. Choose the data types that best suit the information being captured.
- Consider Nullability: Determine if attributes can have null values or if they must always have a value. Some attributes may be optional and allow for null values, while others may be mandatory and require a value for every entity instance.
- Analyze Relationships and Dependencies: Consider the relationships and dependencies between entities. Identify attributes that are dependent on or related to other entities or attributes. For example, an attribute like “order date” may be dependent on the “order” entity and the associated “customer” entity.
- Consider Derived Attributes: Identify attributes that can be derived or calculated based on other attributes or entities. Derived attributes are not stored directly but are computed dynamically. Multiplying “quantity” by “unit price”, you can obtain an attribute such as “total price”.
- Validate with Stakeholders: Collaborate with stakeholders, subject matter experts and end-users to validate the identified attributes. Gather feedback and ensure that the identified attributes accurately capture the necessary information and align with the requirements of the system.
Remember that attribute identification is an iterative process and it may require refinement and adjustments as you gain more insights and feedback. It’s important to involve relevant stakeholders throughout the process to ensure that the identified attributes meet the needs of the system and accurately describe the entities being modeled.
Best Practices for Defining Entities and Attributes
Adherence to best practices when defining entities and attributes within a data model or database is vital in order to maintain consistency, clarity and effectiveness. Here are some guidelines for delimiting attributes and entities:
- Clearly Define Entities: Clearly define each entity, including its purpose, boundaries and relationships with other entities. Use concise and meaningful names that accurately represent the entity.
- Use Singular Nouns for Entities: Name entities using singular nouns to maintain consistency and avoid confusion.
- Choose Descriptive Attribute Names: Use descriptive attribute names that clearly indicate the information they represent. Avoid ambiguous or vague names that may lead to confusion or misinterpretation. Instead of “data”, use “date_of_birth”.
- Use Consistent Naming Conventions: Adopt a consistent naming convention for entities, attributes and other database elements. Improve readability, maintenance costs and ease-of-understanding. For example, you can use camel case (e.g., first Name) for attribute names.
- Identify and Use Appropriate Data Types: Choose appropriate data types for attributes to accurately represent the type of data being stored. This ensures data integrity and efficient storage. For example, use “integer” for whole numbers, “varchar” for variable-length text for date values.
- Use Constraints to Enforce Data Integrity: Apply constraints such as primary key, foreign key, uniqueness and referential integrity to maintain data integrity and enforce business rules. These constraints help ensure accurate and reliable data.
- Avoid Redundant Attributes: Eliminate redundant attributes by properly normalizing the data. Redundant attributes can lead to data inconsistencies, inefficiencies and potential update anomalies.
- Document Entities and Attributes: Maintain thorough documentation that describes each entity and its attributes. Document the purpose, characteristics, relationships and constraints associated with each entity and attribute. This documentation serves as a reference for developers, administrators and other stakeholders.
- Consider Future Scalability and Extensibility: Anticipate future needs and consider the scalability and extensibility of entities and attributes. Design entities and attributes in a way that accommodates potential changes or additions without requiring significant modifications to the database structure.
- Validate and Refine with Stakeholders: Collaborate with stakeholders, subject matter experts and end-users to validate the defined entities and attributes. Gather feedback and refine the definitions based on their input and requirements.
Adopting these best practices will assist in building an accurate database or data model which accurately represents all the entities and attributes within your system.
Uniqueness
Uniqueness is crucial when creating entities or attributes for use in data models, helping maintain data integrity by eliminating duplication. Here are a few strategies for handling uniqueness:
- Primary Key: Assign a primary key to each entity to ensure its uniqueness. A primary key is a unique identifier for each instance of an entity and is used to distinguish one entity instance from another. It can be a single attribute or a combination of attributes that uniquely identify each entity instance.
- Unique Constraints: Apply unique constraints to attributes that need to be unique within an entity or a combination of attributes. Unique constraints ensure that the values in the specified attribute(s) are unique across all entity instances. This prevents duplicate data from being entered into the database.
- Data Validation: Implement data validation mechanisms to enforce uniqueness during data entry or modification. Use validation rules and checks to ensure that the values entered for unique attributes are not already present in the database.
- Indexing: Create indexes on attributes that require unique lookups or queries for performance optimization. Indexes facilitate faster searching and retrieval of data, particularly when querying for unique values.
- Avoid Redundancy: Avoid storing redundant data that could lead to non-uniqueness. Redundant data increases the likelihood of inconsistencies and duplication. Normalize the data and ensure that each attribute holds only relevant and unique information.
- Data Integrity Constraints: Define and enforce referential integrity constraints when establishing relationships between entities. This ensures that foreign key attributes referencing a primary key in another entity maintain uniqueness and integrity.
- Use Database Features: Utilize unique features provided by the database management system (DBMS) to enforce uniqueness. DBMSs offer mechanisms such as unique indexes, constraints and functions specifically designed to maintain uniqueness in the data.
- Validation with Stakeholders: Validate the uniqueness requirements with stakeholders and subject matter experts to ensure that the defined uniqueness constraints align with the business rules and requirements of the system.
By implementing these best practices, you can maintain data integrity and ensure that entities and attributes are uniquely identified and represented in your database or data model.
Relevance
Data modeling and database design entail understanding the difference between attributes and entities; why is this so vitally important?
- Data Modeling: Entities and attributes are fundamental building blocks of data modeling. Data models represent the structure, relationships and properties of data within a system. Properly identifying and defining entities and attributes ensures that the data model accurately represents the real-world domain it is intended to capture.
- Database Design: Entities and attributes are key elements in designing the structure of a database. Entities become tables or collections in the database and attributes become columns or fields within those tables. Clear identification and definition of entities and attributes facilitate the creation of a well-organized and efficient database schema.
- Data Integrity: Entities and attributes play a crucial role in ensuring data integrity. By properly defining entities and their attributes, you can establish constraints and rules that maintain the consistency and correctness of data. For example, primary key attributes ensure the uniqueness of entity instances, while foreign key attributes maintain referential integrity between related entities.
- Data Manipulation and Retrieval: Understanding entities and attributes enables efficient data manipulation and retrieval. By organizing data into entities and assigning appropriate attributes, you can perform operations such as inserting, updating and deleting data more effectively. Querying and retrieving data becomes easier when the relationships between entities and their attributes are well-defined.
- System Understanding and Communication: Clear identification of entities and attributes aids in understanding the system or domain being modeled. It facilitates effective communication between stakeholders, developers and designers, as everyone can have a common understanding of the entities and their properties. This clarity ensures that everyone is on the same page when discussing system requirements, data representation and functionality.
- Data Analysis and Reporting: Properly defined entities and attributes support meaningful data analysis and reporting. By organizing data into logical entities and capturing relevant attributes, you can perform analytics, generate insights and create informative reports based on specific data elements.
Understanding the difference between entities and attributes is crucial for accurate and effective data modeling, database design, data integrity, data manipulation, system understanding and data analysis. It forms the foundation for creating well-structured, maintainable and efficient databases that align with the requirements and objectives of the system being designed.
Consistency
Consistency is of vital importance in terms of managing and designing databases, for several reasons. Here is why:
- Data Integrity: Consistency ensures data integrity by maintaining the correctness and accuracy of data. It ensures that the data stored in the database is reliable and free from contradictions or conflicts. Consistent data promotes confidence in the information stored and helps avoid data quality issues.
- Reliability and Trustworthiness: Consistent data instills trust in the system and the information it provides. Users rely on accurate and consistent data to make informed decisions, perform analysis and drive business processes. Inconsistencies in data can lead to errors, confusion and lack of confidence in the system.
- Interoperability and Integration: Consistency facilitates interoperability and integration between different systems and databases. When data is consistent across systems, it becomes easier to exchange and integrate information seamlessly. This enables smooth collaboration and sharing of data between different applications and databases.
- Querying and Reporting: Consistent data allows for accurate querying and reporting. When data follows consistent formats, structures, and conventions, it becomes easier to write queries and generate meaningful reports. Consistency in attribute names, data types and relationships simplifies data retrieval and analysis.
- Maintenance and Updates: Consistency simplifies the maintenance and updates of the database. When data and its associated attributes follow consistent patterns, it becomes easier to apply changes, perform updates and ensure the overall stability of the database. Consistency reduces the chances of errors and conflicts during maintenance tasks.
- User Experience: Consistent data models and structures improve the user experience. Users find it easier to understand and navigate through the database when entities and attributes are consistently defined. Consistency also helps in training users, as they can rely on predictable patterns and behaviors within the system.
- Scalability and Growth: Consistency supports scalability and growth of the database. When data follows consistent standards and conventions, it becomes easier to add new entities, attributes or relationships to accommodate future needs. Consistency in the database design helps in maintaining a flexible and extensible system.
- Collaboration and Communication: Consistency enhances collaboration and communication among stakeholders involved in the database. When everyone follows consistent naming conventions, entity definitions and attribute definitions, it improves clarity and understanding. Consistency in communication leads to smoother collaboration and reduced misunderstandings.
By prioritizing consistency in database design, you can ensure data integrity, reliability, interoperability, accurate querying, simplified maintenance, improved user experience, scalability and effective collaboration. Consistency is essential for creating a robust and trustworthy database system that meets the needs of the users and the organization.
Final words on entity and attribute
Entities and Attributes are the cornerstones of data management, providing the structure and organization needed for databases to function effectively. Understanding their roles and relationships is crucial for businesses to harness the power of data for strategic decision-making and growth.

